Table of contents
1. Pipeline / Workflow
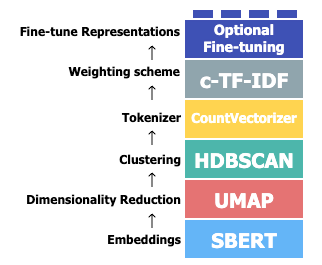
- Embed documents(需根据语言调整)
- Convert documents to numerical representations.
- Help tremendously in subsequent clustering task.
- Two useful models:
"all-MiniLM-L6-v2"for English"paraphrase-multilingual-MiniLM-L12-v2"for other languages
- 一个中文的词向量模型(但效果貌似不行):
spacy.load("zh_core_web_sm") - Other embedding models: 1. Embeddings - BERTopic (maartengr.github.io)
- Dimensionality Reduction(一般默认)
- Cluster models have difficulty handling high dimensional data due to the curse of dimensionality → That’s why we need dimension reduction.
- UMAP is the default DR algorithm for BERTopic (can also choose PCA).
- Other DR algorithms: 2. Dimensionality Reduction - BERTopic (maartengr.github.io)
- Clustering(一般默认)
- HDBSCAN is set to be the default clustering algorithm → because it can identify outliers where possible. Hence, documents will not be forced into a cluster where they might not belong (that’s why we get topic “-1” in the final result).
- Other clustering algorithms: 3. Clustering - BERTopic (maartengr.github.io)
- Tokenizer (i.e. Bag-of-words; 可以对其深度定制化)
- Now cluster is the unit of analysis, because we want to extract “a topic” from a cluster.
- Hence, combine all documents in a cluster into a single document.
- Then, count how often each word appears in each cluster → bag-of-words.
- This step is independent to previous steps → In other words, you can use the original document for clustering, and then use the processed document for topic extraction!
- Other vectorizers: 4. Vectorizers - BERTopic (maartengr.github.io)
- For Chinese: FAQ - BERTopic (maartengr.github.io)
- Weighting Scheme (i.e. Topic representation; 一般默认)
- After tokenization, we want to know what makes one cluster different from another (what = which words → the descriptions of the topic).
- Modify TF-IDF such that it considers topics instead of documents:
-

- Fine-tune Representations (optional)
- Further fine-tune these c-TF-IDF topics using GPT, T5, KeyBERT, Spacy, and other techniques.
2. Display Results
| Methods of topic_model | Description |
|---|---|
| .get_topic_info() | Get information about each topic including its ID, frequency, and name. |
| .get_topic(0) | Return top words for a specific topic (topic 0 here) and their c-TF-IDF scores. |
| .get_representative_docs(0) | Extract the best three representing documents for a given topic (topic 0 here). |
| .visualize_topics() | Visualize topics, their sizes, and their corresponding words. |
| .visualize_hierarchy(top_n_topics=30) | 前30个topics的层级关系 |
3. Two Approaches for Chinese Modeling
## tokenizer: 中文分词函数;stop_words: 停用词列表
vectorizer_zh = CountVectorizer(tokenizer=lambda x:jieba.lcut(x),
stop_words=get_stopwords())Approach 1: 用原始文档做embedding-DR-clustering,然后用处理后文档做topic representation —— “Passing the CountVectorizer after training” - 本质是fine-tuning
topic_model = BERTopic(language="chinese (simplified)")
topics, probs = topic_model.fit_transform(docs)
topic_model.update_topics(docs, vectorizer_model=vectorizer_zh)Approach 2: 直接用处理后文档做embedding-DR-clustering-topic representation —— “Passing the CountVectorizer before training”
topic_model = BERTopic(language="chinese (simplified)", vectorizer_model=vectorizer_zh)
topics, probs = topic_model.fit_transform(docs)