Markowitz, D. M., Hancock, J. T., & Bailenson, J. N. (2023). Linguistic Markers of Inherently False AI Communication and Intentionally False Human Communication: Evidence From Hotel Reviews. Journal of Language and Social Psychology. https://doi.org/10.1177/0261927x231200201
Table of contents
- Problem statement
- Literature review
- Data
- Automated text analysis
- Measures
- Analytic plan
- Results
- Reproduction
Problem statement
- Diff in linguistic signals between AI-generated content and human-generated content
- More specifically, human-generated hotel reviews were compared to AI-generated hotel reviews to identify how such text types are different in terms of content (e.g., emotion), style (e.g., analytic writing, adjectives), and structure (e.g., readability).
- Discuss two types of false: inherently false (AI) vs. intentionally false (human)
Literature review
AI-mediated communication
- H1: AI-generated text will be more affective than human-generated text.
- [Style] Analytic Writing Index (e.g. function words) → proxy for elaborate thinking
- [Style] Descriptiveness (rate of adjectives)
- [Structural complexity] Readability
Deception Research
- Deception has a different linguistic signature than honesty - channel matters.
- AI - inherently false ~ misinformation, different from intentionally false of human-generated content
Data
Equivalent prompts:
- 400 truthful human-written reviews
- 400 deceptive human-written reviews
- 400 AI-generated hotel reviews (ChatGPT 3.5)
Automated text analysis
- LIWC
- Coh-Metrix
- R package quanteda.textstats
Measures
- [content] rate of affect terms
- [style] analytic writing
- [style] adjectives
- [structure] readablity
Analytic plan
- Linear mixed model
- fixed effect = review type (AI or decep or truth)
- random effect = hotel name
- Classification model
- classification acc of distinguishing between AI-generated text and human text
Results
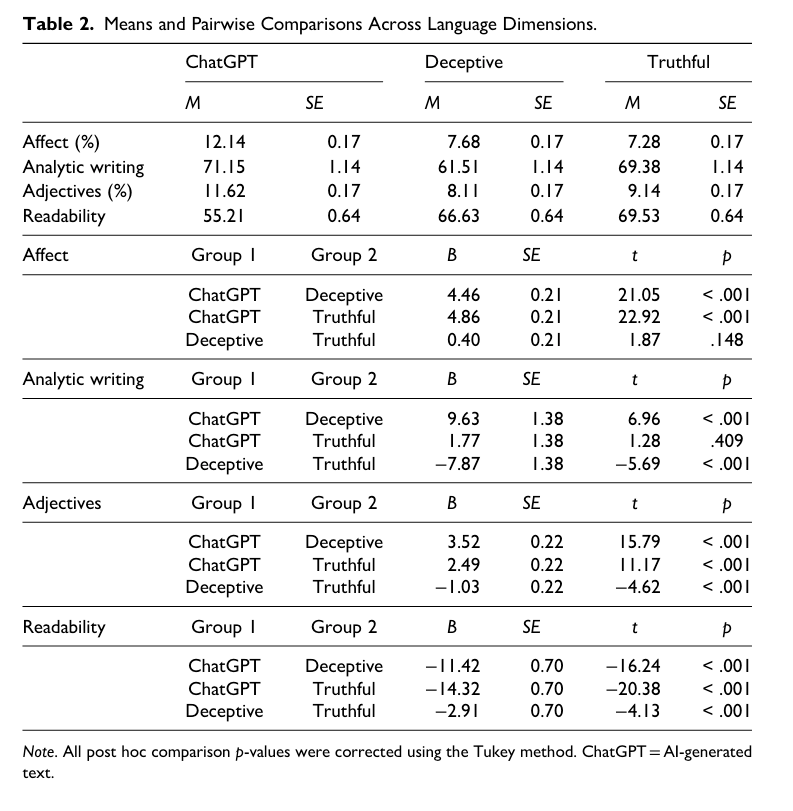
linguistic signals:
- AI-generated content is more affective than deceptive human content (and truthful).
- AI-generated content is more analytic than deceptive human content.
- AI-generated content is more descriptive than deceptive human content (and truthful).
- AI-generated content is less readable than deceptive human content (and truthful).
classification accuracy:
- “88.5%”
Reproduction
library(readr)
library(tidyverse)
library(lme4)
library(lmerTest)# https://osf.io/nrjcw/
data = read_csv("./data/hotel_reviews_AIMC_OSF_FINAL.csv")
subdata = data %>%
transmute(readability, Analytic, adj, Affect,
type = as.factor(type), hotel = as.factor(hotel))# DV: Affect
# IV: type
# random intercept: hotel
mixed.mod1 = lmer(Affect ~ type + (1|hotel), data = subdata)
summary(mixed.mod1)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: Affect ~ type + (1 | hotel)
Data: subdata
REML criterion at convergence: 6056.1
Scaled residuals:
Min 1Q Median 3Q Max
-2.4440 -0.6484 -0.0988 0.5421 6.0932
Random effects:
Groups Name Variance Std.Dev.
hotel (Intercept) 0.149 0.386
Residual 8.985 2.998
Number of obs: 1200, groups: hotel, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 12.137 0.173 74.974 70.17 <2e-16 ***
typedeceptive -4.461 0.212 1178.000 -21.05 <2e-16 ***
typetruthful -4.857 0.212 1178.000 -22.92 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) typdcp
typedeceptv -0.613
typetruthfl -0.613 0.500# sig01: the random effect of between group variation
# sigma: the residual random effect
confint(mixed.mod1)| 2.5 % | 97.5 % | |
|---|---|---|
| .sig01 | 0.1083217 | 0.6458311 |
| .sigma | 2.8780972 | 3.1200044 |
| (Intercept) | 11.7980907 | 12.4756093 |
| typedeceptive | -4.8766642 | -4.0458358 |
| typetruthful | -5.2727142 | -4.4418858 |
subdata2 = subdata %>%
mutate(type2=relevel(type, ref='truthful'))
mixed.mod11 = lmer(Affect ~ type2 + (1|hotel), data = subdata2)
summary(mixed.mod11)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: Affect ~ type2 + (1 | hotel)
Data: subdata2
REML criterion at convergence: 6056.1
Scaled residuals:
Min 1Q Median 3Q Max
-2.4440 -0.6484 -0.0988 0.5421 6.0932
Random effects:
Groups Name Variance Std.Dev.
hotel (Intercept) 0.149 0.386
Residual 8.985 2.998
Number of obs: 1200, groups: hotel, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 7.2795 0.1730 74.9735 42.089 <2e-16 ***
type2chatGPT 4.8573 0.2120 1178.0000 22.916 <2e-16 ***
type2deceptive 0.3961 0.2120 1178.0000 1.869 0.0619 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) ty2GPT
type2chtGPT -0.613
type2decptv -0.613 0.500Interpretations:
- The mean of Affect for ChatGPT messages is 12.14
- The mean of Affect for Deceptive messages is 12.137-4.461=7.68
- The mean of Affect for Truthful messages is 12.137-4.857=7.28
- The difference in the mean Affect scores between ChatGPT messages and Deceptive messages is 4.46, which is significantly greater than 0
- The difference in the mean Affect scores between ChatGPT messages and Truthful messages is 4.86, which is significantly greater than 0
- The difference in the mean Affect scores between Deceptive messages and Truthful messages is 0.40, which is not significantly greater than 0
# DV: Analytic
# IV: type
# random intercept: hotel
mixed.mod2 = lmer(Analytic ~ type + (1|hotel), data = subdata)
summary(mixed.mod2)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: Analytic ~ type + (1 | hotel)
Data: subdata
REML criterion at convergence: 10548.5
Scaled residuals:
Min 1Q Median 3Q Max
-3.0281 -0.6291 0.1752 0.7354 1.9173
Random effects:
Groups Name Variance Std.Dev.
hotel (Intercept) 7.008 2.647
Residual 382.915 19.568
Number of obs: 1200, groups: hotel, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 71.146 1.144 71.441 62.215 < 2e-16 ***
typedeceptive -9.633 1.384 1178.000 -6.962 5.58e-12 ***
typetruthful -1.766 1.384 1178.000 -1.277 0.202
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) typdcp
typedeceptv -0.605
typetruthfl -0.605 0.500# DV: adj
# IV: type
# random intercept: hotel
mixed.mod3 = lmer(adj ~ type + (1|hotel), data = subdata)
summary(mixed.mod3)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: adj ~ type + (1 | hotel)
Data: subdata
REML criterion at convergence: 6168.9
Scaled residuals:
Min 1Q Median 3Q Max
-2.4988 -0.6994 -0.0880 0.6096 4.6913
Random effects:
Groups Name Variance Std.Dev.
hotel (Intercept) 0.06235 0.2497
Residual 9.93075 3.1513
Number of obs: 1200, groups: hotel, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 11.6243 0.1672 110.5426 69.54 <2e-16 ***
typedeceptive -3.5195 0.2228 1178.0000 -15.79 <2e-16 ***
typetruthful -2.4894 0.2228 1178.0000 -11.17 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) typdcp
typedeceptv -0.667
typetruthfl -0.667 0.500# DV: readability
# IV: type
# random intercept: hotel
mixed.mod4 = lmer(readability ~ type + (1|hotel), data = subdata)
summary(mixed.mod4)Linear mixed model fit by REML. t-tests use Satterthwaite's method [
lmerModLmerTest]
Formula: readability ~ type + (1 | hotel)
Data: subdata
REML criterion at convergence: 8933.4
Scaled residuals:
Min 1Q Median 3Q Max
-6.8669 -0.5154 0.0740 0.6653 2.6982
Random effects:
Groups Name Variance Std.Dev.
hotel (Intercept) 3.255 1.804
Residual 98.784 9.939
Number of obs: 1200, groups: hotel, 20
Fixed effects:
Estimate Std. Error df t value Pr(>|t|)
(Intercept) 55.2123 0.6401 52.7172 86.26 <2e-16 ***
typedeceptive 11.4165 0.7028 1178.0000 16.24 <2e-16 ***
typetruthful 14.3212 0.7028 1178.0000 20.38 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Correlation of Fixed Effects:
(Intr) typdcp
typedeceptv -0.549
typetruthfl -0.549 0.500