Table of contents
- What is moderated mediation?
- What is mediated moderation?
- Example: New Easterlin Paradox regarding Education
- References
What is moderated mediation?
When an indirect effect of X on Y through M is moderated, we call this phenomenon moderated mediation (Hayes, 2013, p.358).
The following are models from the Hayes SPSS PROCESS Macro. ✅ means being moderated and ❌ means not being moderated.
Model 7 (first-stage moderation):
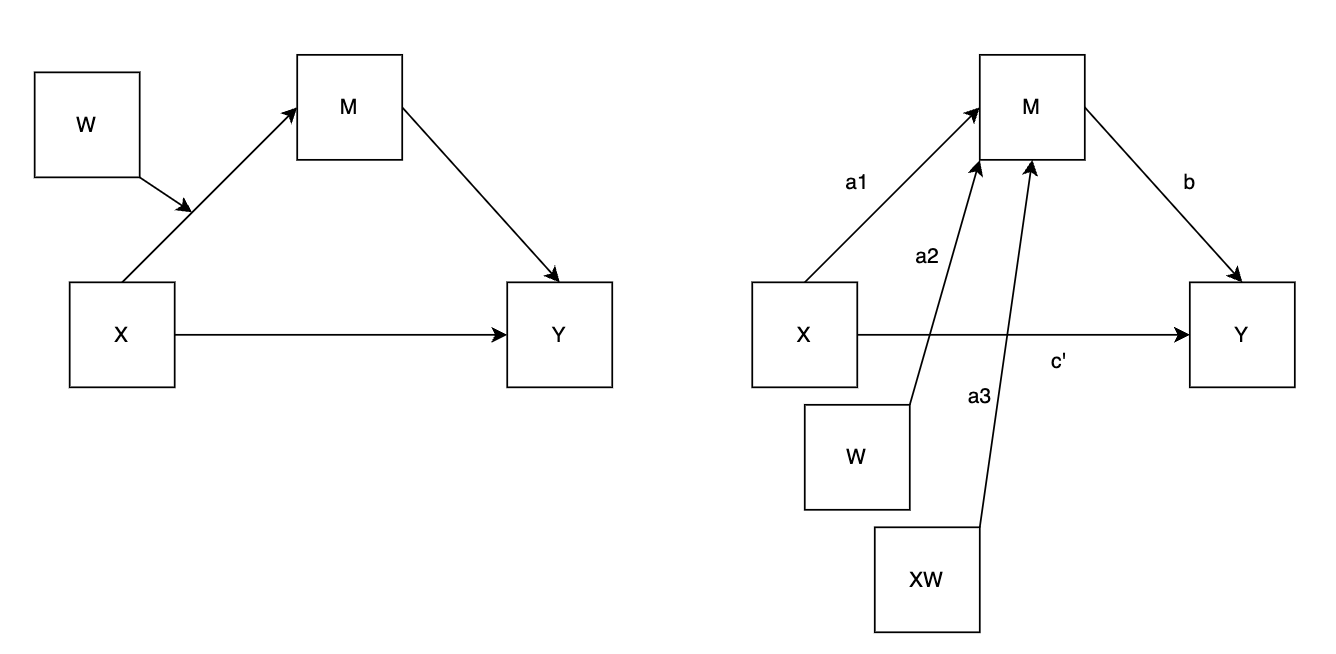
- ❌ Direct effect (of X on Y):
- ✅ Indirect effect (of X on Y through M):
Model 14 (second-stage moderation):
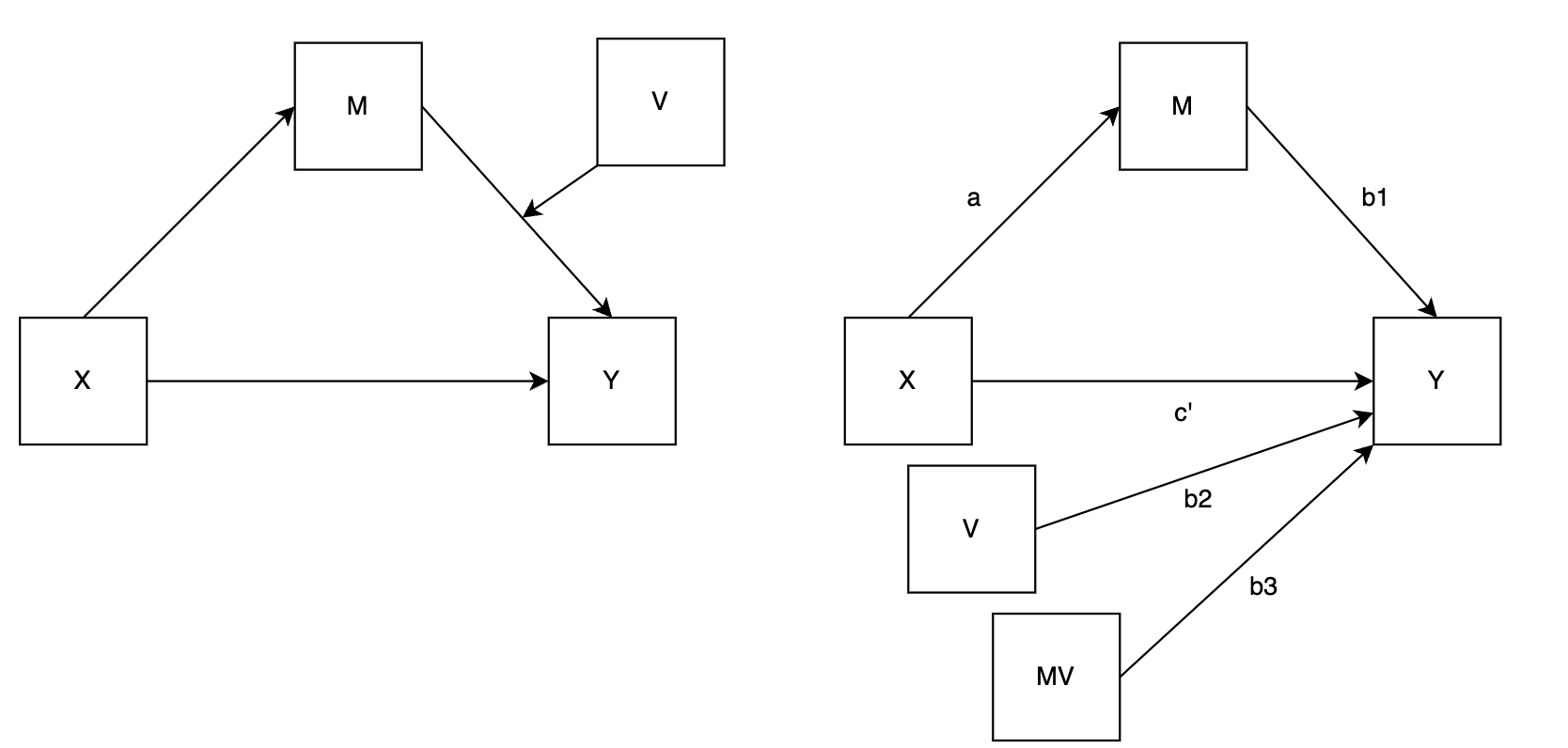
- ❌ Direct effect (of X on Y):
- ✅ Indirect effect (of X on Y through M):
Model 8 (first-stage moderation + moderation on direct effect):
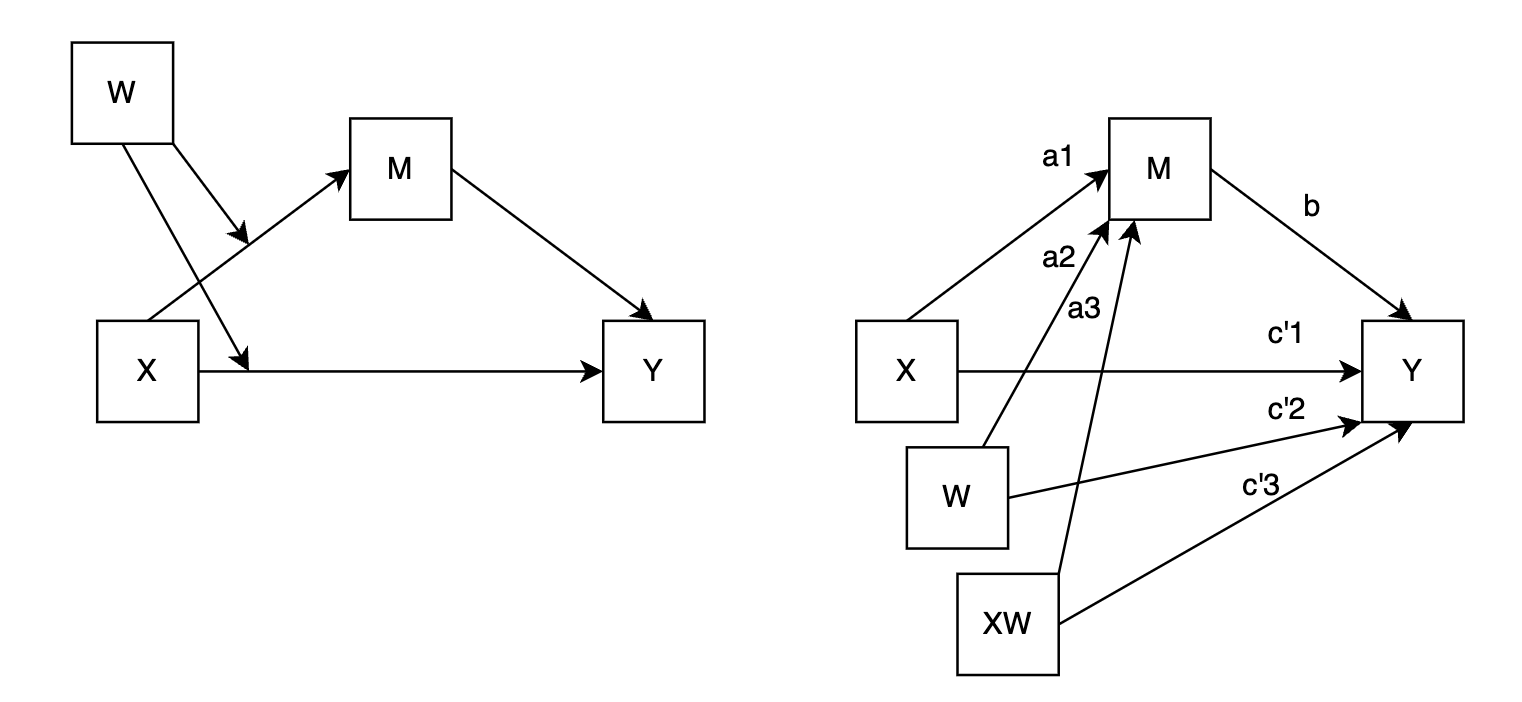
- ✅ Direct effect (of X on Y):
- ✅ Indirect effect (of X on Y through M):
Model 15 (second-stage moderation + moderation on direct effect):
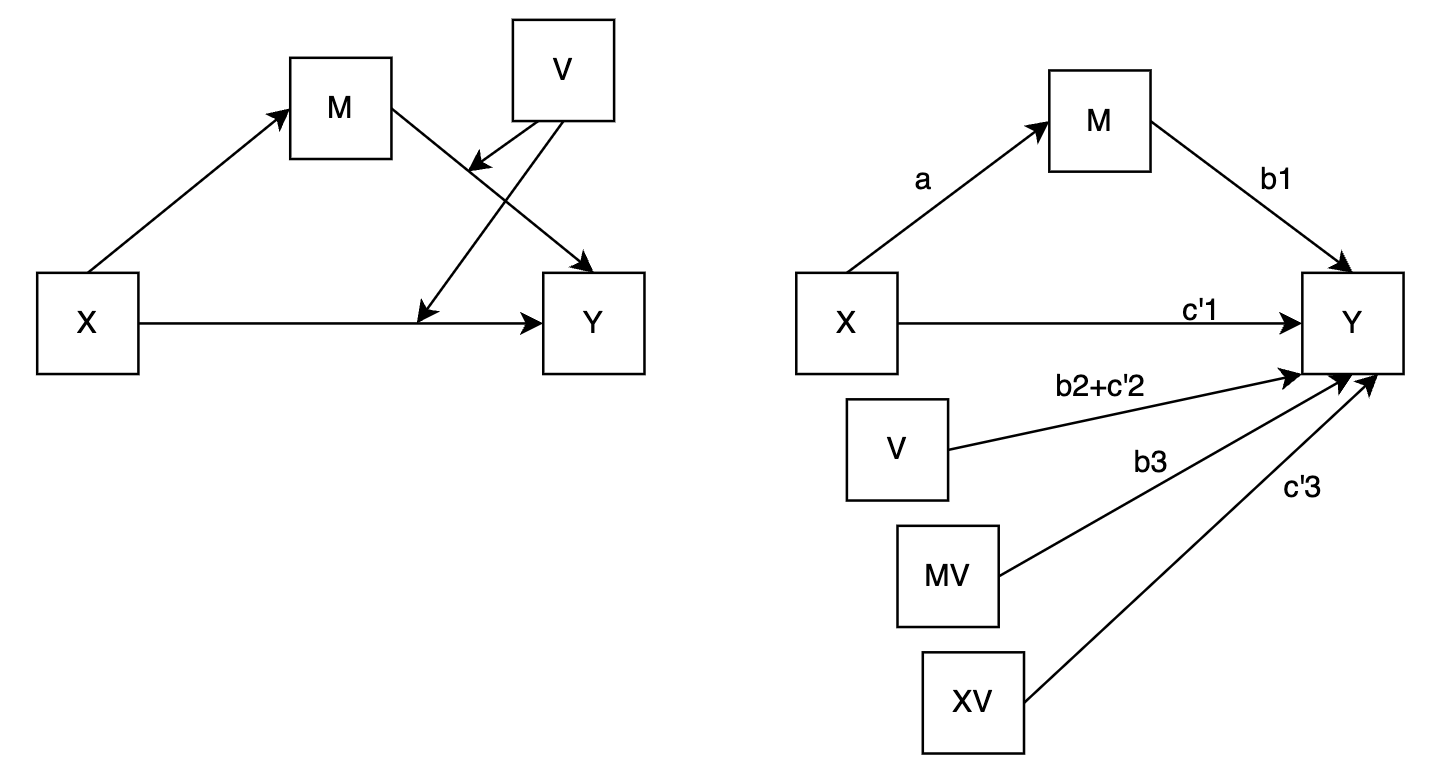
- ✅ Direct effect (of X on Y):
- ✅ Indirect effect (of X on Y through M):
What is mediated moderation?
A similar-sounding phenomenon is mediated moderation, which refers to the scenario in which an interaction between X and some moderator W on Y is carried through a mediator M … However, I argue that rarely can much meaningful come out of a mediated moderation analysis, because conceptualizing a process in terms of mediated moderation misdirects attention toward a variable in the model that actually doesn’t measure anything (Hayes, 2013, p.358).
Example: New Easterlin Paradox regarding Education
The “Easterlin Paradox” refers to the phenomenon that once income reaches a certain level, individual’s subjective well-being no longer increases with further income growth.
Education is supposed to be an approach for achieving happiness, but in recent years in China, it seems that increased education levels have not led to higher levels of well-being - this appears to be a new Easterlin paradox.
This paper introduces a mediator, cultural consumption (文化消费), to clarify the relationship between education and subjective well-being, with family income (家庭收入) as a moderator.
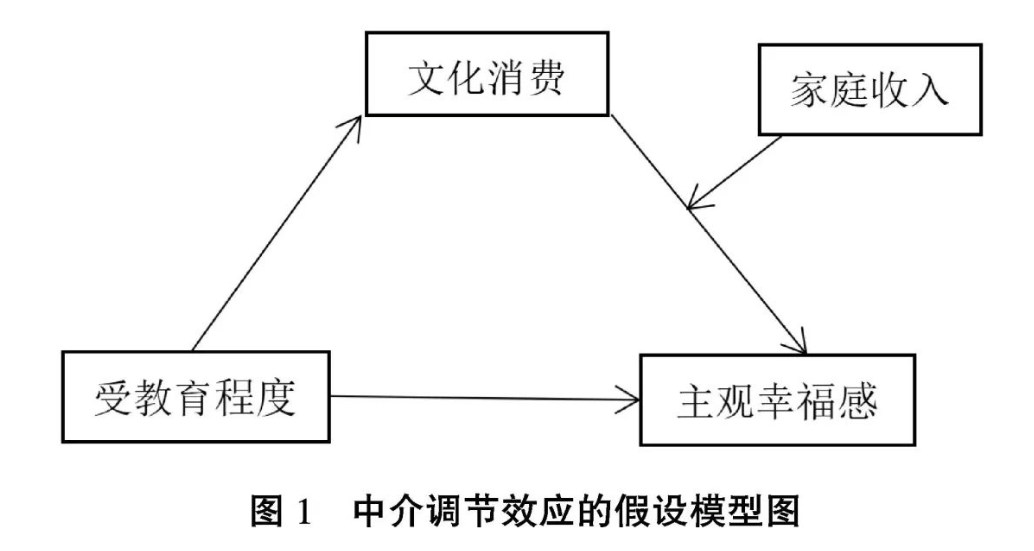
由于本研究中的调节变量“家庭收入”为连续变量(continuous),因此我们将检查在收入均值上一个标准差与下一个标准差这两个位置上间接效应的大小和显著性(注意lavaan的语法):
model.2 = '
# Regressions
cul_cons ~ a*edu + gender + age + health + party + hukou + prov + married + med_ins + old_ins
well_being ~ b*cul_cons + c*edu + d*log_inc + e*cul_cons:log_inc + gender + age + health + party + hukou + prov + married + med_ins + old_ins
# Mean of inc
log_inc ~ log_inc.mean*1
# Variance of inc
log_inc ~~ log_inc.var*log_inc
# Indirect effects
indirect.SDbelow := (b + e*(log_inc.mean-sqrt(log_inc.var)))*a
indirect.SDabove := (b + e*(log_inc.mean+sqrt(log_inc.var)))*a
# Direct effects
direct := c
# Total effects
total.SDbelow := direct + indirect.SDbelow
total.SDabove := direct + indirect.SDabove
# Proportion
prop.mediated.SDbelow := indirect.SDbelow / total.SDbelow
prop.mediated.SDabove := indirect.SDabove / total.SDabove
'
model.2 = sem(model.2, data=df, se="bootstrap", bootstrap=1000)
print(summary(model.2, fit.measures=TRUE))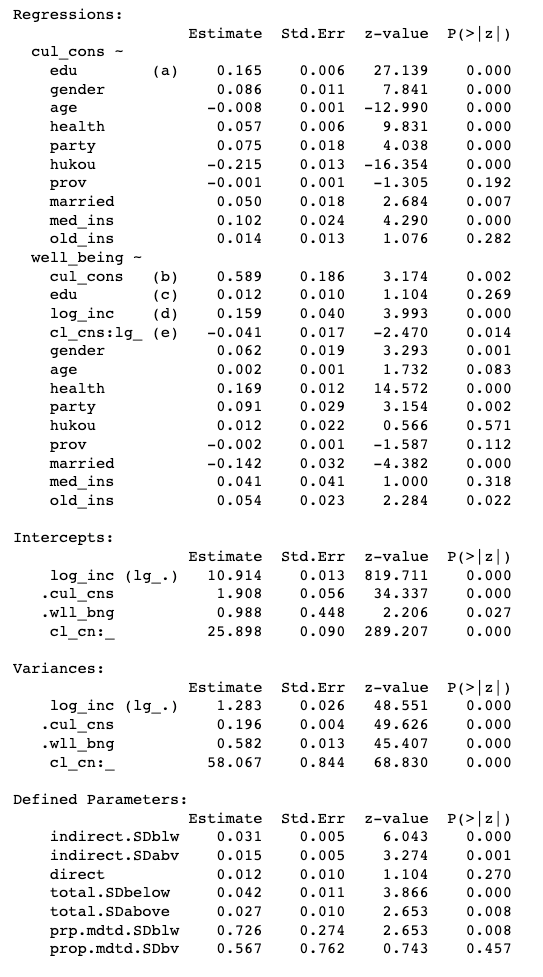
Interpretation:
- 家庭收入负向调节文化消费与幸福感的关系(e=-0.041,p<0.05),说明收入越高,文化消费对幸福感的正向效应越低。
- 文化消费的中介效应(indirect effect)在低收入和高收入两个条件之下均显著:低收入条件下为0.031(p=0.000),高收入条件下为0.015(p=0.001)。
Full note on this paper: 👉 click here 👈
References
- Hayes, A. F. (2013). Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach. Guilford Publications.
- 李彤,张学敏,周杰.“伊斯特林悖论”的教育再探——教育影响主观幸福感的中介效应[J].教育与经济,2023,39(04):44-53.